4.3 Downscaling Methods#
In principle, each of the bias-correction methods described in Section 4.1 could be used to downscale climate model output to a finer resolution grid using gridded observations. One would simply need to re-grid (interpolate) the model output to the (finer) resolution of the gridded observations and apply (for example) Quantile Delta Mapping to each grid cell independently. Doing this is problematic, because it can result in distortion of spatial covariance structures (i.e. Hnilica et al. [2017], Maraun [2013]). For this reason, other methods for gridded statistical downscaling have been developed to correct biases at multiple sites/grid cells and preserve these covariance structures.
4.3.1 Bias Correction and Spatial Disaggregation#
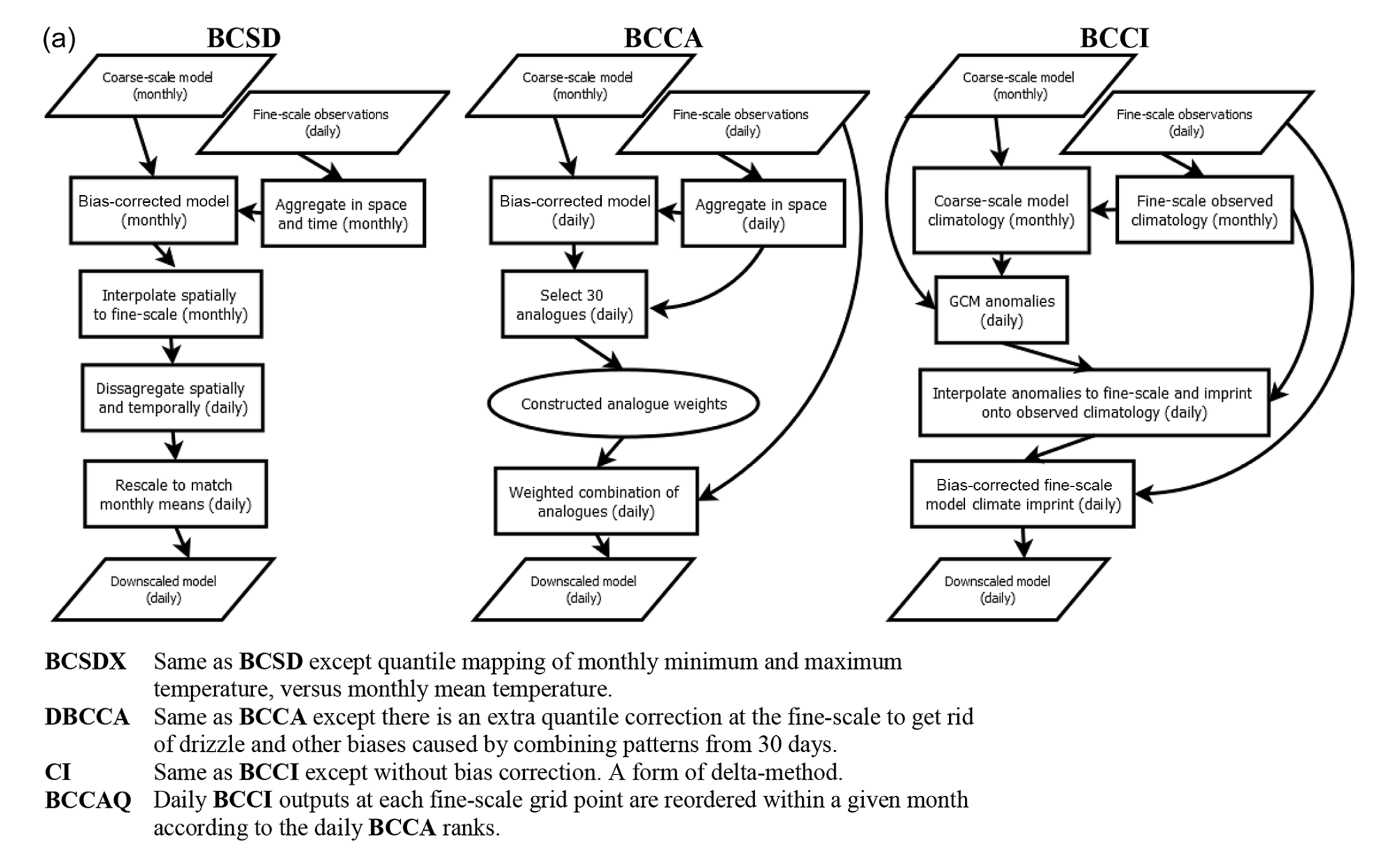
Also referred to as Bias Correction and Spatial Downscaling, BCSD uses monthly output combined with daily high-resolution gridded observations to produce gridded statistical downscaling output [Wood et al., 2004]. First, the daily gridded observations are coarsened to the model grid and aggregated to monthly means (monthly totals for precipitation). These coarsened/aggregated observed monthly means are used to bias-correct the GCM output using Empirical Quantile Mapping. These bias-corrected monthly means are then interpolated to the high-resolution grid of the observations. Finally, daily downscaled output is produced by the following procedure: For each GCM month, an observed month is selected at random, and the daily values for this observed month are adjusted additively (multiplicatively for precipitation) to match the downscaled monthly mean (total). Because of it has been around for so long, BCSD has been widely implemented but has significant limitations. First, because it uses monthly mean GCM data as inputs, the downscaled results cannot reflect changes at sub-monthly timescales, such as changes to extreme weather. Here we describe BCSD only for pedagogical purposes - its use is not recommended in the UTCDW.
4.3.2 Climate Imprints#
The Climate Imprint (CI) method is a sort of delta method applied to gridded data. A GCM monthly climatology is constructed from a historical reference simulation and this climatology is subtracted to produce daily GCM anomaly patterns. These GCM anomalies are interpolated to the fine-resolution grid of the observations and added to the observed historical monthly climatology. A more advanced version of CI called BCCI (Bias Corrected CI) is described in Werner and Cannon [2016], where a quantile mapping bias correction is applied to the CI outputs. Neither CI nor BCCI are methods recommended by the UTCDW, but CI is a key step in the BCCAQv2 method used by PCIC to produce their statistically downscaled climate scenarios for Canada (described in the following subsection).
4.3.3 Analogue Methods#
4.3.3.1 Constructed Analogues#
Constructed Analogue (CA) based methods produce downscaled data by aggregating observed data from real days that best match a particular simulated day. As described in Werner and Cannon [2016], high-resolution observations are coarsened to the model grid, and the \(N\) (typically \(N\) = 30) days most similar to the given simulated day are selected. Typically anomaly fields (i.e. with the daily or monthly climatology subtracted) are used for each data product, instead of the total fields, to avoid the mean bias of the model influencing the selection of analogue days. The original authors [Hidalgo et al., 2008] measure similarity using RMSE, but other similarity metrics are also supported in xclim. When searching for candidate observed patterns, only those within \(\pm\) 45 days of the day to be downscaled are included (i.e. for a simulated April 15th, only observed days from March 1st and May 30th are included, across all years in the observational dataset, for a pool of 90 \(\times N_{YRS,OBS}\) candidate observed analogue days for each simulated day).
|
|---|
Illustration of observed pattern selection, from Abatzoglou (2011) and Abatzoglou and Brown [2012] |

The optimal linear combination of these \(N\) observed anomaly patterns to reproduce the simulated anomaly pattern is determined using ridge regression, and finally, the downscaled anomalies are produced using the same linear combination on the high-resolution observed anomaly patterns [Maurer et al., 2010]. The literature is unclear regarding best practices for reimposing the climatology onto the downscaled anomalies in the setting of future climate projections, since it mainly focuses on evaluating the skill of this method for the historical period. Regardless, the use of stand-alone CA is not recommended for downscaling future climate projections, so this ambiguity is not consequential for the UTCDW.
|
|---|
Illustration of analogue construction, from Abatzoglou (2011) and Abatzoglou and Brown [2012] |

4.3.3.2 Bias-Corrected Constructed Analogues#
Maurer et al. [2010] proposed an adapted version of CA that corrects biases in the coarse-resolution GCM output using quantile mapping, before selecting the observed analogues. Total fields are compared to observations in the CA step, instead of anomalies, because biases relative to the observed climatology have already been adjusted. When using BCCA for downscaling future projections, Detrended Quantile Mapping is used for bias correction, with separate trends estimated for each month of the year [Hiebert et al., 2018].
Werner and Cannon [2016] expand on BCCA with two additional analogue-based methods. Double BCCA (DBCCA) applies a second quantile mapping bias correction after the CA step, to adjust any biases introduced by combining observed days using a linear combination. For example, combining precipitation patterns from multiple days can result in persistent small but finite amounts of precipitation, similar to the “drizzle” bias in GCMs where the frequency of days with zero precipitation is severely underestimated. DBCCA has also been referred to as BCCAP, or “Bias Corrected Constructed Analogues with Postprocessing” [Murdock et al., 2014].
Because of its strength at representing both spatial patterns and location-wise distributions, and its ease of implementation (relative to BCCAQ), DBCCA/BCCAP, with Quantile Delta Mapping as the post-processing step, is the recommended method of spatial statistical downscaling for the UTCDW.
4.3.3.3 BCCA with Quantile Mapping Reordering#
The second method proposed by Werner and Cannon [2016] is called BCCAQ, or “Bias-Corrected Constructed Analogues with Quantile Mapping Reordering”. This method is similar to BCCAP but performs better regarding the three metrics by which Murdock et al. [2014] assessed the skill of different methods of statistical downscaling: reproducing the observed temporal sequencing, probability distributions, and spatial variability.
BCCAQv2 involves running both the BCCI (using QDM for bias correction, v1 used EQM) and BCCA methods independently. Then, for each month of the BCCI/QDM output, the values at each grid cell for each day are re-ordered to match the rank structure of the BCCA data for days in that same month, using a method called the “Schaake Shuffle” [Clark et al., 2004]. The daily QDM data is sorted in increasing order, and the BCCA output is ranked. The sorted QDM output is then indexed by the ranks of the BCCA. This re-ordering reduces the excessive spatial smoothness of the QDM output [Murdock et al., 2014, Werner and Cannon, 2016] and retains the accurate representation of spatial structures in BCCA.
Clark et al. [2004] give the following example of the Schaake Shuffle. Let \(X\) and \(Y\) be two time series of data, with \(\chi\) and \(\gamma\) being the sorted versions of \(X\) and \(Y\) respectively, i.e.
Where subscript \((i)\) indicates the \(i\)’th smallest value of the set. In our case, \(X\) is the QDM output for a given month and grid cell, and \(Y\) is the BCCA output for that same month and grid cell. Let \(B\) be the vector of indices of \(Y\) that map the values of \(Y\) to the corresponding value of \(\gamma\) (\(\gamma_{i} = Y_{B_{i}}\)); i.e. the ranks of \(Y\). Then the re-ranked values of \(X\) are given by:
A schematic of each of these gridded downscaling methods is provided in Figure 3a of Werner and Cannon [2016], shown below.